
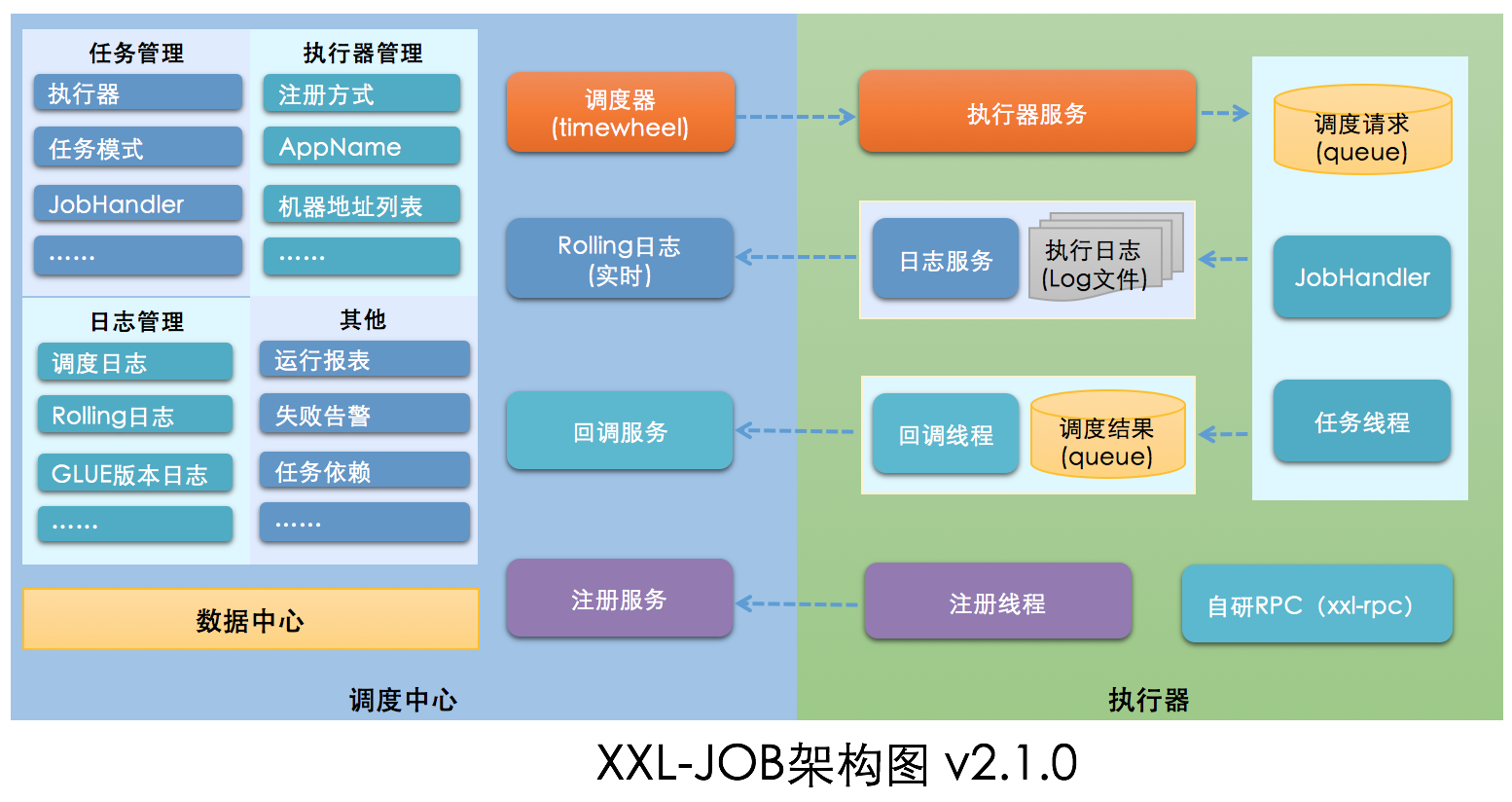
架构图
xxl-job的jar包
- xxl-job-admin: 调度中心(包含了前端html)
- xxl-job-core:公共组件包(调用中心、执行器都会依赖这个包)
部署
调度中心部署注意的点
- DB配置要保持一致
- 集群机器时钟要一致(需要做时间同步)
- 使用nginx做负载均衡
- 如何是用docker在k8s中部署的话,只需要部署一个deployment,然后扩容成多份即可
执行器部署
- 执行器我的理解,应该是每个项目组有一个执行器这个微服务工程,然后在这个工程里去写各种的定时任务的handler,这些handler再通过feign调用改项目组其他微服务
- 执行器工程需要依赖
xxl-job-core - 配置调度中心的地址
- 配置appName(xxl-job中,如果不配置此name,则执行器不会自动注册到调度中心)
- 配置执行器的ip(一般会在多网卡的情况下配置)
- 配置执行器的port(这两个配置是给调度中心通知执行器去执行的)
- 配置token(可选)
- 配置日志路径(执行器的日志路径,后面可以考虑换成我们的ELK)
- 配置日志保存的天数(如果换成ELK的话,可以不用这个配置了)
名词解释
执行器
- 执行器应该是以项目为维度划分的,一个项目有一个执行器
- 一个执行器有多个任务
任务
- 任务关联在执行器上
任务路由策略
- FIRST(第一个):固定选择第一个机器;
- LAST(最后一个):固定选择最后一个机器;
- ROUND(轮询):;
- RANDOM(随机):随机选择在线的机器;
- CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
- LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
- LEAST_RECENTLY_USED(最近最久未使用):最久为使用的机器优先被选举;
- FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
- BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
- SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
任务的运行模式
- BEAN模式:任务以JobHandler方式维护在执行器端;需要结合 “JobHandler” 属性匹配执行器中任务;
- GLUE模式(Java):任务以源码方式维护在调度中心;该模式的任务实际上是一段继承自IJobHandler的Java类代码并 “groovy” 源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务;
- GLUE模式(Shell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “shell” 脚本;
- GLUE模式(Python):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “python” 脚本;
- GLUE模式(PHP):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “php” 脚本;
- GLUE模式(NodeJS):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “nodejs” 脚本;
- GLUE模式(PowerShell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “PowerShell” 脚本;
阻塞处理策略
- 单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
- 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
- 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
二次开发
选择在xxl-job的V2.1.2版本上进行开发
该版本的jobHandler写法比较方便
由原来基于JobHandler类任务开发方式,优化为支持基于方法的任务开发方式
ui的修改
- 目前xxl-job的调度中心的界面需要重写
SDK
- 现阶段,SDK中应该只需要提供自动注册、通知执行器等功能
- 后期可以提供方法:让业务方能查询到某个任务在某一次的执行状态等等方法
痛点
- xxl-job的代码规范有点乱
- xxl-job-core的职责不清晰,调度中心、执行器都会依赖这个jar包,我们需要进行拆分
- 需要重写xxl-job的前端
- 日志的查看
- sdk包的职责定义
- 配置如何与nacos进行集成
- 改造后的任务调度中心如果对xxl-job进行升级